

Our scientific future
With great power comes great responsibility


I remember the first time I used ChatGPT. It was mind-blowing. I think I WhatsApped my wife and a few friends, saying something had fundamentally shifted. I don’t think they believed me initially, but they soon came around.
I had an even more profound experience a few weeks ago when using Claude Code for the first time. Is this what exponential progress looks like? Because what I can now ask it to do, I could not do a few months ago. It would have been utterly unimaginable two years ago.
For the uninitiated, two examples. About a week ago, I told Claude Code to recreate and expand an academic paper I published last year in the South African Journal of Science.1 I uploaded my dataset and R scripts to a folder, and over the next few minutes watched it redo months of work. After a few hours – I was busy with other stuff too – I had a completely rewritten and, more importantly, improved paper.
I have explored more plausible research leads in the last few weeks than in the last few years. I know there are sceptics – is this really research? – but I have the papers to back it up. Take the second example: Sugnet Lubbe is a statistician at Stellenbosch whose research centre has been at the frontier of biplots, a statistical classification tool. A few years ago, I mentioned to her that her tool might be useful for our rich Cape Colony data. We met once or twice, but life got in the way, and nothing happened. So, over the weekend, I asked Claude to write the paper. It produced an excellent first draft. The results, I think, overturn a long-held belief about farm structure in the Colony – results which Dieter von Fintel and I will now interrogate further, obviously with the help of Claude.
As I have tried to explain before, it is not just that these tools make us more productive; it is that they allow us to ask questions we would not have asked before. That is the superpower. Trying has always been expensive – in time and effort. Now it is not.
This is both scary and incredibly exciting. It is scary because what will we as scientists do in the future, when swarms of agents can ask – and answer – loads of interesting questions? But it is exciting because we get answers to questions we could not answer before and, thrillingly, get to ask questions we could not even imagine before.
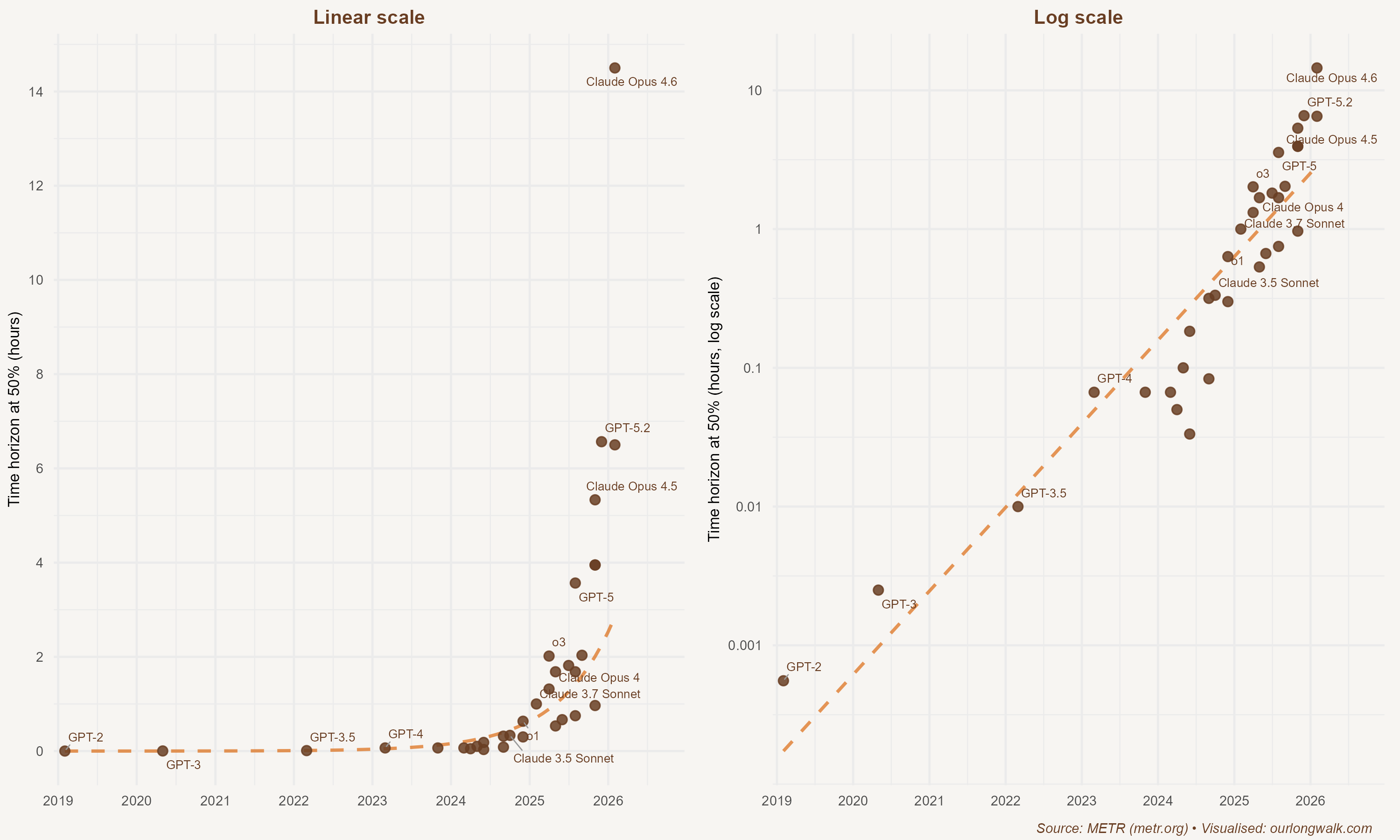
The speed at which this technology has improved is difficult to convey without pictures, and pictures matter because humans find it hard to comprehend exponential change. On the left, in a linear scale, the METR ‘time horizon’ series – a measure of how long an AI model can work autonomously on a task before it fails – looks almost flat for years and then suddenly shoots up. Nothing happens, until everything happens. On the right, the same data on a log scale tells a different story: steady, compounding progress, year after year, until it becomes visible in everyday work. A longer time horizon is precisely what allows the tool to carry a workflow, not just complete a task.
A recent NBER working paper by Demirer, Horton, Immorlica, Lucier, and Shahidi offers a useful way to think about this. Most real work is not a list of separate tasks. It is a workflow – a chain where each step depends on the last. In economics research, you do not just ‘run a regression’; you choose a question, find or build data, clean it, write code, interpret outputs, draft the story, make the figure, respond to a referee, and do it all again. If any one link fails, the chain breaks.
What matters is not whether an AI can do one step occasionally, but whether it can do several adjacent steps reliably enough that you stop supervising every hand-off. Once the model crosses a reliability threshold, you can let it run a longer stretch and only verify at the end. In short: a modest improvement in accuracy can unlock a disproportionately large change in autonomy, because it lets the model run longer chains without collapsing. What looks like incremental progress in capability becomes a step-change in what you can actually delegate.
This is exactly what I experienced. ‘Recreate and expand’ worked because the model can now run a long enough slice of the research chain – data, code, prose, figures, robustness checks – that my role shifts from producer to editor-in-chief. Jason Crawford, writing about his experience with coding agents, describes this as humanity ‘stepping up into management’. That captures it precisely. The researcher does not disappear. The researcher becomes the manager of tireless, slightly junior research assistants who never sleep – but who still need a boss with judgement.
Very few knowledge workers – and firms – are prepared for the step-change this will cause. This is especially true of universities. Andy Hall recently tweeted that Claude Code is coming for academia ‘like a freight train’. He points to projects aiming to write one thousand empirical papers, ‘research swarms’ that generate hundreds of drafts, and even ‘LLM councils’ for peer review. In the language of the NBER paper, these are simply longer and wider chains: not one assistant helping with one link, but systems running whole stretches of the pipeline in parallel.
Scott Cunningham has done the arithmetic on what this means for publishing. Project APE at the University of Zurich has already generated over two hundred fully automated empirical economics papers. If researchers can now produce at five or ten times their previous rate, the roughly 3,800 annual publication slots across economics journals will face a flood. Acceptance rates, already around five per cent at top journals, could fall below one per cent. The bottleneck shifts from producing papers to evaluating them – and our current peer review system, staffed by overworked volunteers, cannot scale. It is an arms race: each researcher rationally speeds up, but collectively nobody gains a relative advantage while the system buckles.
At this point, the temptation is to tell the standard story: AI will replace scientists; the end is nigh; abandon ship. I do not think that will happen. David Bessis, in a letter to a PhD student anxious about AGI, offers a more useful framing. We are entering a mass extinction event for legacy career strategies – the comfortable equilibrium where technical mastery and incremental output could be laundered into status. If intellectual labour means scanning the literature, applying known techniques, and producing competent prose, then yes: machines will do it, and increasingly well.
But there is a deeper reason not to despair. Carlo Cordasco makes a striking argument against Daron Acemoglu’s influential model for AI regulation, which recommends deliberately limiting AI precision to preserve human knowledge. The problem is that the model treats the structure of knowledge as fixed. It can track how existing skills degrade but cannot capture how entirely new competencies might emerge. Cordasco’s analogy is sharp: it is like analysing the printing press while assuming that the only forms of knowledge that matter are the ones that existed before 1440. From within a world of manuscript copying, you could reasonably worry that scribes would lose their craft. You could not possibly anticipate the scientific revolution, mass literacy, newspapers, or the restructuring of entire economies around the printed word. Even a Nobel laureate’s carefully reasoned model can miss the point, because the most profound effects of a new technology are not the ones you can anticipate. Restricting the tools to preserve what we already know how to do may be precisely the wrong instinct.
But original research is not the same as valuable research. LLMs can make bad ideas look respectable, and it becomes cheap to produce work that is ‘publishable’ but pointless. In South Africa, we already have distorted incentives that reward volume – the Department of Higher Education pays universities a subsidy for each unit of research output. If a single academic can produce thousands of papers, the marginal paper is worth almost nothing, but the subsidy cheque keeps arriving. The bottleneck shifts from producing text to producing trusted knowledge.
So what does a scientist do in this world? More than ever, we have to own the upstream questions. Why this question? Why this dataset? Why should anyone care? If it is clear and useless, it is useless. AI will make it easier than ever to be clear. It will not automatically make our work valuable. That remains a human problem – judgement, taste, ethics.
For Africa, this is both an extraordinary opportunity and a serious risk. African researchers often possess something no AI can generate: intimate knowledge of local contexts, institutions, and data that the global research machine overlooks. A historian in Accra who understands precolonial trade networks, an economist in Nairobi who knows how mobile money works in rural markets – these scholars can now use AI to ask questions at a scale previously reserved for well-funded Northern universities. The playing field, for the first time, is tilting. But only if the institutions tilt with it.
The future of science will not be decided by whether we ‘allow’ AI into research. It is already embedded in the work. What matters now is the norms and institutions we build around it: transparency about what the model did, open data and code, and a more muscular culture of replication. And while we are reforming institutions, here is a low-hanging fruit that Adam Mastroianni has been hammering on: if the public paid for the research, it should not be paywalled. Major publishers maintain profit margins of around forty per cent by controlling access to publicly funded knowledge. In a world where AI submissions are about to overwhelm peer review, funnelling public money to for-profit gatekeepers is not just unfair; it is absurd. For African universities spending scarce budgets on journal subscriptions, the case is even more urgent.
These same tools can flood the world with plausible-looking nonsense. The real danger is not that machines will make us redundant. It is that machines will let us exploit incentive structures built for a different era. South Africa’s research subsidy system – designed decades ago to encourage a then-underproductive academy – needs a fundamental rethink.
If we want the exhilarating version of this future – the one where we ask better questions, test them more rigorously, and learn faster – then we have to be more demanding of ourselves and of our institutions. Reform the incentives. Open the publications. Invest in evaluation, not just production. The computational power is here. The question is whether those in power will update our institutions, responsibly and quickly, for this new scientific future.
Fourie, J., 2025. Inequality In the Cape Colony, 1685-1844. South African Journal of Science, 121(11-12), pp.1-9.
Jy is meer hoopvol as ek.
Interesting! I really like the printing press analogy. One issue is that, as I read recently, Gutenberg went bankrupt because there was no market for 100 copies of the same book. Ahead of his time.
These things take a long time to shake out, hopefully not too painfully in this case.