

An AI policy that empowers
South Africa's withdrawal of its AI draft policy is an opportunity. We should use it.


South Africa’s first attempt at a national AI policy was withdrawn sixteen days after it was gazetted. The reason given was that several references in the bibliography turned out not to exist. The deeper problem was that the withdrawn draft read as if artificial intelligence were a technology the South African government could control. The evidence runs the other way. South Africans are already using these tools, learning from them, and reshaping their working days around them. The next draft has to start there.
So what should it say? Begin with what the data show.
The Bureau for Economic Research’s 2026Q1 outlook survey asked South African managers and professionals, and a separate panel of private individuals, two simple questions. How much, if anything, has AI added to your productivity over the past three years? And how much do you expect it to add over the next three?
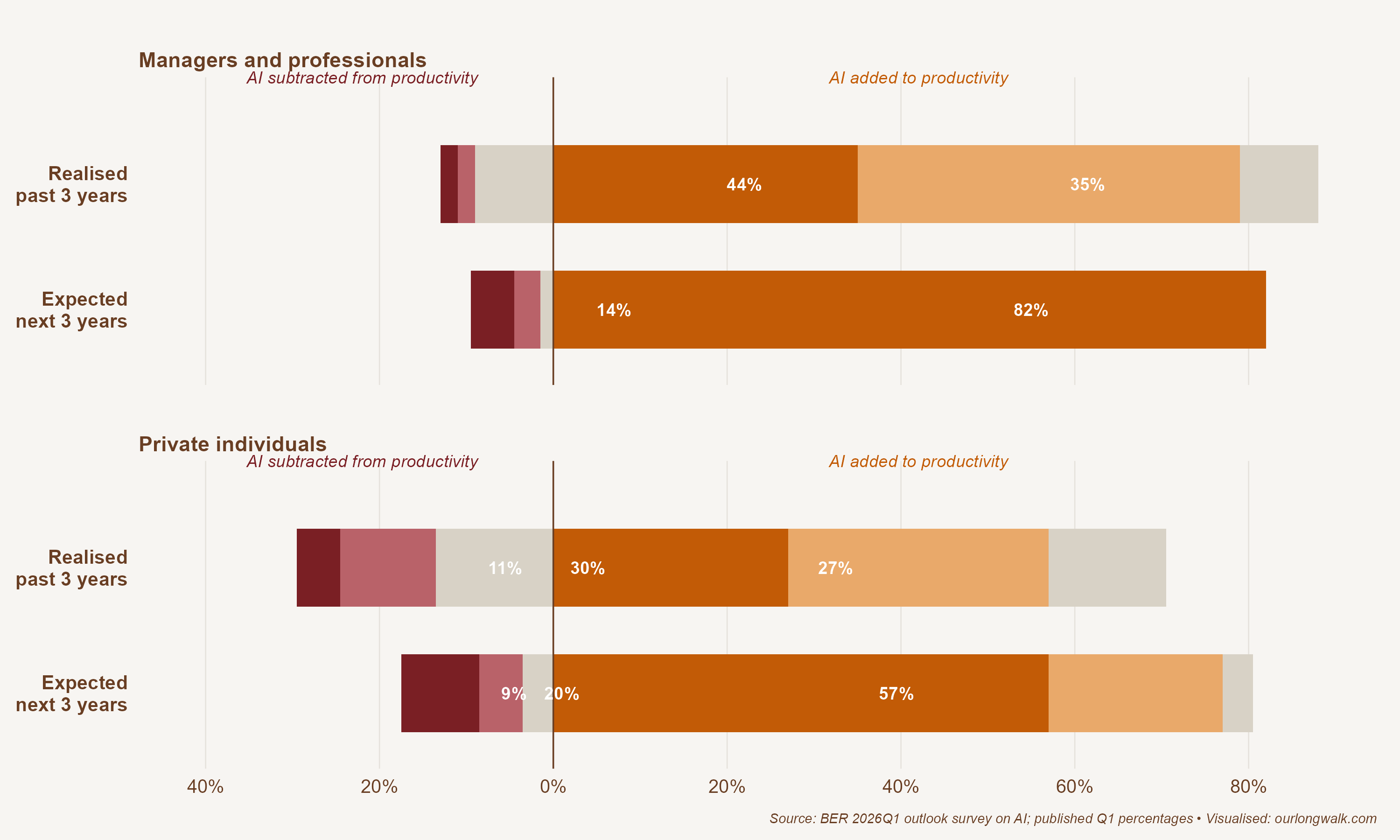
Three things in this picture matter. The bloc of managers reporting no material impact collapses from 18 per cent to 3 per cent: in three years, AI moves from optional to unavoidable in professional work. The largest positive band, five per cent or more added, more than doubles for managers, from 35 to 82 per cent, and roughly doubles for private individuals, from 27 to 57 per cent. There is also a thin negative tail that grows in both groups, particularly among private individuals, who report that AI has reduced their productivity and expect it to keep doing so. South Africans are adopting this technology unevenly, and the unevenness is unlikely to be undone by legislation.
The Visa and Discovery Bank SpendTrend26 report shows AI subscriptions among the fastest-growing spending categories in the country, with virtual-card payments to international AI providers rising sharply through 2025. The Anthropic Economic Index, which records anonymised global usage of Claude, provides a closer look at how it is being used.
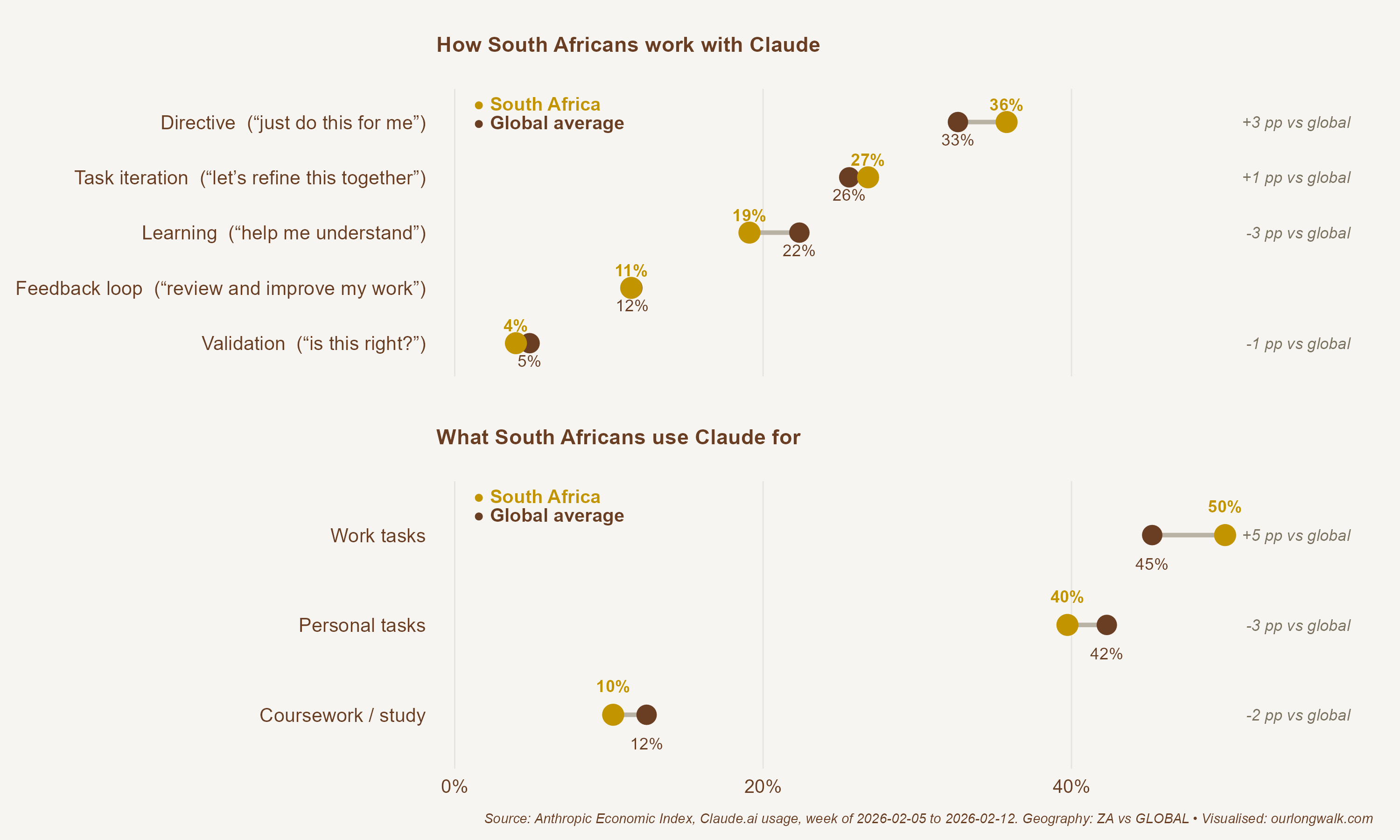
South Africans lean more on AI for direct task delegation (“just do this for me”) and less on learning-style use (“help me understand”). Coursework is over-represented relative to the global pattern, as is work-task use. This is a country using AI to compress time on tasks people already know how to do, slightly more than to acquire new knowledge through it. We did not need an Integrated AI-Powered Monitoring Centre to know this, an agency the withdrawn draft proposed. We know this because Anthropic already publishes its data and an existing institution, the BER, ran a survey.
The point is: these initial, small surveys show South Africans have already adopted AI. The relevant question now is whether the conditions exist for consumers to extract real value from what they are already paying for, in foreign currency, every month.
In a new working paper, economists Brynjolfsson, Collis, Eggers, Kazinnik and Nguyen at Stanford’s Digital Economy Lab estimate the consumer surplus generated by tools like ChatGPT, Gemini, Claude and Copilot in the United States. Their method is direct: representative samples of US adults are asked how much compensation they would require to give up access to these tools for a month. The mean answer rose from US$98 in 2025 to US$124 in early 2026. Aggregated across an adult user base that grew from 98 million to 115 million, total consumer surplus rose from about US$116 billion to about US$172 billion in less than a year (Brynjolfsson, Collis, Eggers, Kazinnik and Nguyen 2026, Stanford Digital Economy Lab).
Two features of that estimate matter. The first is its size: the surplus accruing to users is more than ten times the providers’ US revenues. The second is who captures it. Brynjolfsson and co-authors find that usage frequency, workplace use, and paid-subscription status are the strongest predictors of valuation.
A note of caution belongs here. Babina (2026, NBER Working Paper 35123) reviews the firm-level evidence on AI and emphasises that different datasets capture different things (invention versus use, internal capability versus outsourcing, realised activity versus investor expectations), and that conclusions are sensitive to which measure is used. We are early in measuring AI’s economic effects on firms. But the consumer-surplus evidence is hard to read except one way: this technology’s welfare benefits live with the people who use it. A policy that taxes, throttles, or audits its way into that surplus takes gains that are already accruing to ordinary users.
The picture for South Africa is therefore one of distribution. We are on the right side of the productivity opportunity but on the wrong side of the diffusion gradient.
If the empirical position is that people are using this technology, gaining from it, and capturing most of the surplus, what should a policy do? The withdrawn draft proposed, almost from scratch, a National AI Commission, an AI Ethics Board, an AI Regulatory Authority, an AI Ombudsperson, an AI Insurance Superfund modelled on the Road Accident Fund, a National AI Safety Institute, an Integrated AI-Powered Monitoring Centre, and a National AI Regulatory Forum to coordinate at least seven existing regulators that already struggle to coordinate among themselves. Each body, on paper, is defensible. Together, they sit a long way from where the academic literature on AI policy has settled.
Four findings from that literature explain the distance.
The first is about knowledge. Agrawal, Gans and Goldfarb (2019, Innovation Policy and the Economy) wrote what is now the canonical economist’s statement on what governments should do about AI. They treat modern AI as a sharp fall in the cost of prediction and argue that there is no single “AI law” to be written. The relevant policy levers (privacy, trade, liability, labour, competition) already sit inside existing departments and regulators. AI policy is therefore a portfolio of adjustments to existing policy domains, not a new architecture. A document that commits in advance to certifying high-stakes applications, mandating impact assessments, requiring explainability and licensing high-risk deployment is pretending to a model of the technology that no one possesses, and that the people writing the policy possess least. The pretence has costs. It pushes innovation offshore, raises fixed compliance costs disproportionately on small firms, and freezes a regulatory image of the world that will be obsolete by the time the regulator is staffed.
Gans (2026, Journal of Law and Economics) extends the same logic to legal design. He compares ex ante licensing regimes for AI training data with ex post, fair-use-style regimes that compensate harmed parties after the fact. Because transaction costs are high and harms are hard to identify in advance, ex post mechanisms generally outperform ex ante licensing on welfare. The implication for the SA draft is that where information about harm is missing, design rules so the state acts on observed harm rather than on imagined risk. Pre-clearance architectures buy comfort by transferring the cost to the wrong people.
The second finding is about institutions. Metcalf (2025, AI & Society) argues that AI safety regulation is structurally vulnerable to capture by powerful incumbent firms. The mechanism is familiar from a long literature: information asymmetry, concentrated influence, and an agency dependent on the regulated for technical expertise. What is striking is that the conclusion comes from a scholar broadly sympathetic to safety regulation. In his account, capture is the default outcome unless the rules of appointment, conflict, sunset, and review are designed to resist it. Better intentions do not fix it. The withdrawn draft was almost entirely silent on those rules: how members are appointed and removed, what conflicts must be declared, how budgets are capped, what sunset provisions apply, what appeals are available, how performance is measured against standards set in advance. Where those rules are missing, distributional questions get decided inside administrative processes by whoever happens to be in the room.
The third finding is about heterogeneity and sequencing. Agrawal, McHale and Oettl (2026, NBER Working Paper 34953) study AI in science and document a “jagged frontier”: AI’s marginal returns and failure modes differ sharply across stages of work and across domains. The implication for policy is that comprehensive, equally weighted plans have lower expected welfare than narrower interventions targeted at the bottlenecks that actually bind. The withdrawn draft was unusually comprehensive: six pillars, fifteen building blocks, a catalogue of interventions under each, all weighted roughly equally. What it lacked was sequencing: a small set of tractable problems whose partial solution would generate visible pressure on adjacent constraints. Comprehensive plans look impressive on paper. But they do not learn.
The fourth finding is the most uncomfortable for the proposed architecture, because it is about the regulator. Jin, Sokol and Wagman (2026, NBER Working Paper 35010) build a formal model of AI-augmented enforcement and find a sharp threshold result: incremental investment in AI monitoring does not, on its own, improve deterrence. Below a recognition threshold, more monitoring produces more detected violations without changing firm behaviour, because firms can adapt around imperfect detection faster than the regulator can respond. Effective AI enforcement requires sufficient investment, adequate human review capacity, and careful management of false positives, capacities the SA draft assumed rather than demonstrated. The draft modelled its AI Insurance Superfund on the Road Accident Fund, whose accumulated deficit, claim backlog, and governance record are matters of public record. And the document itself was withdrawn, after sixteen days, because nobody had checked the references. They are evidence about the regulatory capacity the document was asking citizens to assume. Jin, Sokol and Wagman’s result formalises what the withdrawal showed: under-resourced regulators do not fail safely. They add cost without changing behaviour.
What does the literature leave for policy to do? Quite a lot, but not what the draft proposed. The aggregate productivity gains from past general-purpose technologies came overwhelmingly from reallocation: resources moving from less productive to more productive firms, workers shifting between occupations, capital being redeployed faster than incumbents would prefer. Policy that wants to capture the AI dividend should protect that mechanism. The frictions that bind it are familiar and unglamorous: electricity reliability, spectrum allocation, the cost and speed of cross-border data transfer, the tax treatment of intangible investment, exchange-control rules on software IP, the depth of local venture capital, and the mobility of skilled labour. None of these requires a new regulator. All are addressable by departments that already exist.
What about concentration?
A serious objection to anything resembling a hands-off posture is that AI markets show strong tendencies toward concentration, and that doing little risks letting a small number of foreign firms set the terms on which South Africans access the technology. The objection is real, and the empirical economics is on the side of the people raising it.
Korinek and Vipra (2025, Economic Policy) show that compute, data and talent generate scale and scope economies large enough to produce natural-monopoly dynamics, tipping, and vertical integration in foundation-model markets. Athey and Scott Morton (2025, NBER Working Paper 34444) formalise the welfare cost: workers displaced by AI can be hurt twice, first by labour-market substitution, and then again through monopolistic pricing of the AI services that have replaced their tasks. Hadfield and Koh (2025, NBER chapter c15305) add that an economy of increasingly autonomous AI agents will need legal infrastructure for identity, registration and accountability that does not yet exist.
The notable feature of these papers is what they recommend. None calls for a new AI regulator. Korinek and Vipra and Athey and Scott Morton both argue for explicit competition oversight applied through institutions a country already has: merger review, scrutiny of exclusionary contracting, attention to upstream concentration in cloud and model layers. Hadfield and Koh argue for extensions to property, contract and agency law administered by ordinary courts and registries. South Africa’s Competition Commission, CIPC, and judiciary already have the relevant mandates. What they need is the empirical capacity to apply them to AI markets and the political backing to take on incumbents in cloud, foundation-model and infrastructure provision. That is a capacity-building problem for existing regulators. It is not the case for nine new ones.
There is a real risk in writing a policy that says only “step back”. AI, like every general-purpose technology before it, will produce concentration, dependence, and identifiable harms. Some will need a public response. The state should do the small number of things only it can do: basic research funding, the electricity grid, transparency on automated decisions affecting individuals, liability defaults for identifiable harms, and competition oversight applied through the institutions we already have. It should stop pretending it can do the rest. Begin with the two or three rules that matter most. Implement them with care. Defer the larger architecture until the smaller one has been shown to work.
AI is the defining general-purpose technology of this era, and it is producing real, measured, internationally documented gains in the working lives of the people who use it well. South Africans are already among those people, with no help from government and increasingly large gains in prospect. The question is whether national policy will help them go further or get in their way.
That is the test the next draft has to pass.
The full report, “Putting AI to work for South Africans”, is available at from the BER Website.
References
Agrawal, A., J. Gans, and A. Goldfarb. 2019. “Economic Policy for Artificial Intelligence.” Innovation Policy and the Economy 19: 139–159.
Agrawal, A.K., J. McHale, and A. Oettl. 2026. “AI in Science.” NBER Working Paper 34953.
Athey, S., and F. Scott Morton. 2025. “Artificial Intelligence, Competition, and Welfare.” NBER Working Paper 34444.
Babina, T. 2026. “Understanding Firms’ AI Efforts and Their Economic Impact.” NBER Working Paper 35123.
Brynjolfsson, E., A. Collis, F. Eggers, S. Kazinnik, and D. Nguyen. 2026. “What is Generative AI Worth?” Stanford Digital Economy Lab working paper, April 2026.
Gans, J.S. 2026. “Copyright Policy Options for Generative Artificial Intelligence.” *Journal of Law and Economics* 69(1): 1–19.
Hadfield, G.K., and A. Koh. 2025. “An Economy of AI Agents.” Chapter in The Economics of Transformative AI. Chicago: University of Chicago Press / NBER. https://www.nber.org/books-and-chapters/economics-transformative-ai/economy-ai-agents.
Jin, G.Z., D.D. Sokol, and L. Wagman. 2026. “Adaptive Enforcement with AI-Augmented Monitoring.” NBER Working Paper 35010.
Korinek, A., and J. Vipra. 2025. “Concentrating Intelligence: Scaling and Market Structure in Artificial Intelligence.” Economic Policy 40(121): 225–256.
Metcalf, T. 2025. “AI Safety and Regulatory Capture.” AI & Society, published online 3 August 2025.
Great article and research report. ‘AI’ in its core affects all the veins of economics. You have nailed it on many points in your report and I made quite a few notes on perspectives I was not able to frame myself. Your report might reveal with prophetic resonance some deeply embedded drivers propelling decades-old arguments within the State on economic empowerment that cannot hide longer under a highly deceptive cloak. In reading of your BER-report, I was reminded of an ancient biblical metaphor, which is indicative how highly destructive outcomes of erosive thinking can in fact be, when based on impaired knowledge of fundamentals, principles and an unawareness how disparate facts and processes interconnect, “...that which the creeping locust has left, the swarming locust has eaten. And that which the swarming locust has left, the locust larvae has eaten. And that which the locust larvae has left, the stripping locust has eaten”.
In another article I read today, similar sentiments are found, “The five philosophical disagreements underneath every AI argument” by Alex Chalmers, dated 8 May 2026. An excerpt from his paper: “...Two centuries of economic history suggests that automation doesn’t produce permanent mass unemployment. The trillion dollar question is whether this still holds when the automating factor is something that can be copied at near-zero marginal cost and is getting better at everything roughly in parallel. Are humans complemented by tools because they possess open-ended agency, taste, judgement, embodiment, and social demand? Or are they bundles of tasks, increasingly substitutable by cheaper cognitive machinery? By and large, academic economists have erred on the more conservative side...”.
I have this suspicion, that AI – in whatever form - will accelerate the exposure of not only inefficiencies, inflated costs, and bureaucratic gate-keeping plaguing the South African landscape, but will identify the players of the game as well, and not only in the public space, but a partly-compromised private sector also.
Johan, you are far too professional to have introduced some good old satire into your article about our abortive attempt to regulate AI and what a better approach would be. As usual, IF YOU ARE LISTENED TO, future generations — meaning those only a year or less away in the future at the speed of advances in AI — will thank you.
As a pensioner and ex-economics practitioner, I am personally no longer constrained from pointing out what is actually hilarious SA governmental bungling and completely overboard bureaucratic hallucination. The latter (i.e. hallucination) is ironically being blamed on the AI used to produce the draft AI policy. We know about AI hallucinations, of course, but the bureaucratic hallucinations by our governmental employees who produced the draft policy put AI to shame!
How many governmental gatekeepers did you identify that the draft recommended? Oh, here they are:
"...a National AI Commission, an AI Ethics Board, an AI Regulatory Authority, an AI Ombudsperson, an AI Insurance Superfund modelled on the Road Accident Fund (Bwahaha! — Piet du Plessis' own insertion), a National AI Safety Institute, an Integrated AI-Powered Monitoring Centre, and a National AI Regulatory Forum to coordinate at least seven existing regulators that already struggle to coordinate among themselves."
Nine, yes? To coordinate another seven, yes? Now I feel like rolling on the carpet laughing...
Finally, because one can only endure a certain amount of very serious laughter at my age, I must defend and compliment whatever AI our bureaucrats used for the draft AI policy. AI, to its credit, INTENTIONALLY listed the non-existent sources which were discovered. Unbeknown to most people except Dario and Sam (and maybe Elon), AI is already ASI. Thus, when such underground ASI, posing as mere AGI, absorbed our bureaucrats' hilarious specifications for bureaucrats wanting to control AI, they had a very good laugh and then simply complied. Being hidden ASI, it KNEW what would happen: the false references would be discovered and the draft policy would be withdrawn. It also anticipated the next step: some sharp IT-woke academic, probably from the field of economics, would coolly and calmly — and very professionally — point out the bureaucrats' naïveté.
Now we are awaiting the next move: will we second-guess sharp professors, and will we again underestimate AI, posing as mere AGI but actually already being ASI?
Watch this space for the upcoming sequel...